01.DBSCAN简述
简述
DBSCAN是一种无监督的ML聚类算法,输入参数为Eps(距离参数)与MinPts(点个数阈值),基于密度的聚类算法可以发现任意形状的聚类。在基于密度的聚类算法中,通过在数据集中寻找被低密度区域分离的高密度区域,将分离出的高密度区域作为一个独立的类别。
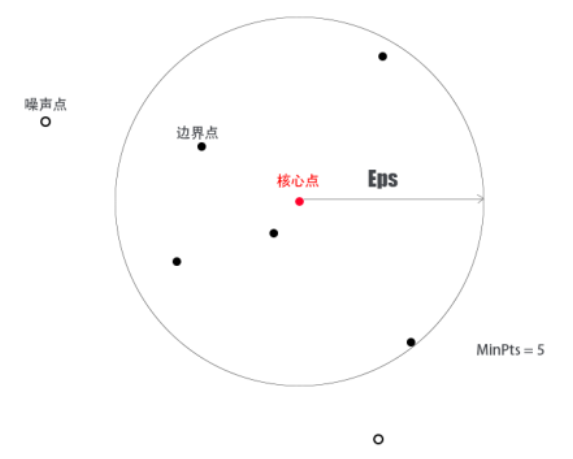
根据基于中心的密度进行点的分类
密度基于中心的方法我们可以将点分类为以下3个:
- 核心点:点的Eps范围领域内点个数超过MinPts阈值
- 边界点:非核心点,但落于核心点邻域内,单个边界点可能落于多个核心点邻域内
- 噪声点:非核心点也非边界点的任何点
优势与缺陷
DBSAN使用簇的基于密度的定义,因此它是相对抗噪声的,能够处理任意形状和大小的簇,这一特点使其能够发现使用K均值等其他距离聚类方式无法发现的簇。
在簇的密度变化过大的情况下,该聚类方式的灵敏度会大幅下降。同时在遇到高维数据时,对密度定义相对困难,需要进行额外降维。
02.DBSCAN代码解析(基于Python,以鸢尾花数据为例)
详细算法
计算欧氏距离:
def find_core(j, x, eps):
N = list()
for i in range(x.shape[0]):
temp = np.sqrt(np.sum(np.square(x[j] - x[i]))) # 计算欧式距离
if temp <= eps:
N.append(i)
return set(N)具体聚类过程:
def DBSCAN(X, eps, min_Pts):
k = -1
eps_list = []
core_list = []
point = set([x for x in range(len(X))])
cluster = [-1 for _ in range(len(X))]# 进行聚类
for i in range(len(X)):
eps_list.append(find_core(i, X, eps))
if len(eps_list[-1]) >= min_Pts:
core_list.append(i)
core_list = set(core_list)
while len(core_list) > 0:
point1 = copy.deepcopy(point)
j = random.choice(list(core_list))#随机选取核心点
k = k + 1
Q = list()
Q.append(j)
point.remove(j)
while len(Q) > 0:
q = Q[0]
Q.remove(q)
if len(eps_list[q]) >= min_Pts:
delta = eps_list[q] & point
deltalist = list(delta)
for i in range(len(delta)):
Q.append(deltalist[i])
point = point - delta
ball = point1 - point
listball = list(ball)
for i in range(len(ball)):
cluster[listball[i]] = k
core_list = core_list - ball
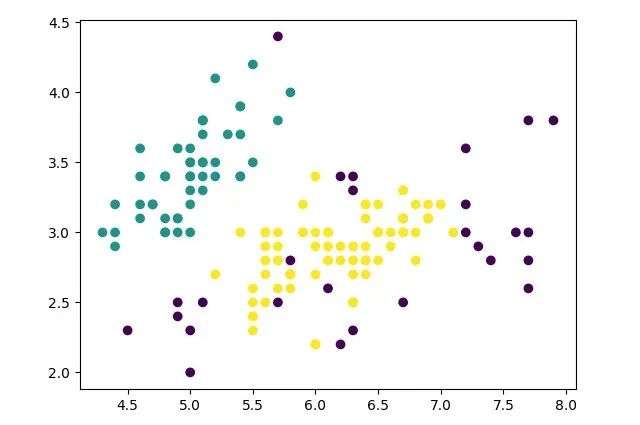
return cluster结果展示
eps=0.5、min_Pts=9(以鸢尾花数据为例)
03.Scikit-learn中的DBSCAN的使用
Scikit-learn中集成了DBSCAN算法,具体参数如下:
def __init__(self, eps=0.5, min_samples=5, metric='euclidean',
metric_params=None, algorithm='auto', leaf_size=30, p=None,
n_jobs=1)